|
CUDA-Q Adapter v0.1
|
|
CUDA-Q Adapter v0.1
|
CUDA-Q (formerly nvq++) provides a programming model that integrates quantum kernels with classical C++ or Python code, enabling hybrid applications. Its compilation flow is built around LLVM, MLIR, and QIR (Quantum Intermediate Representation).
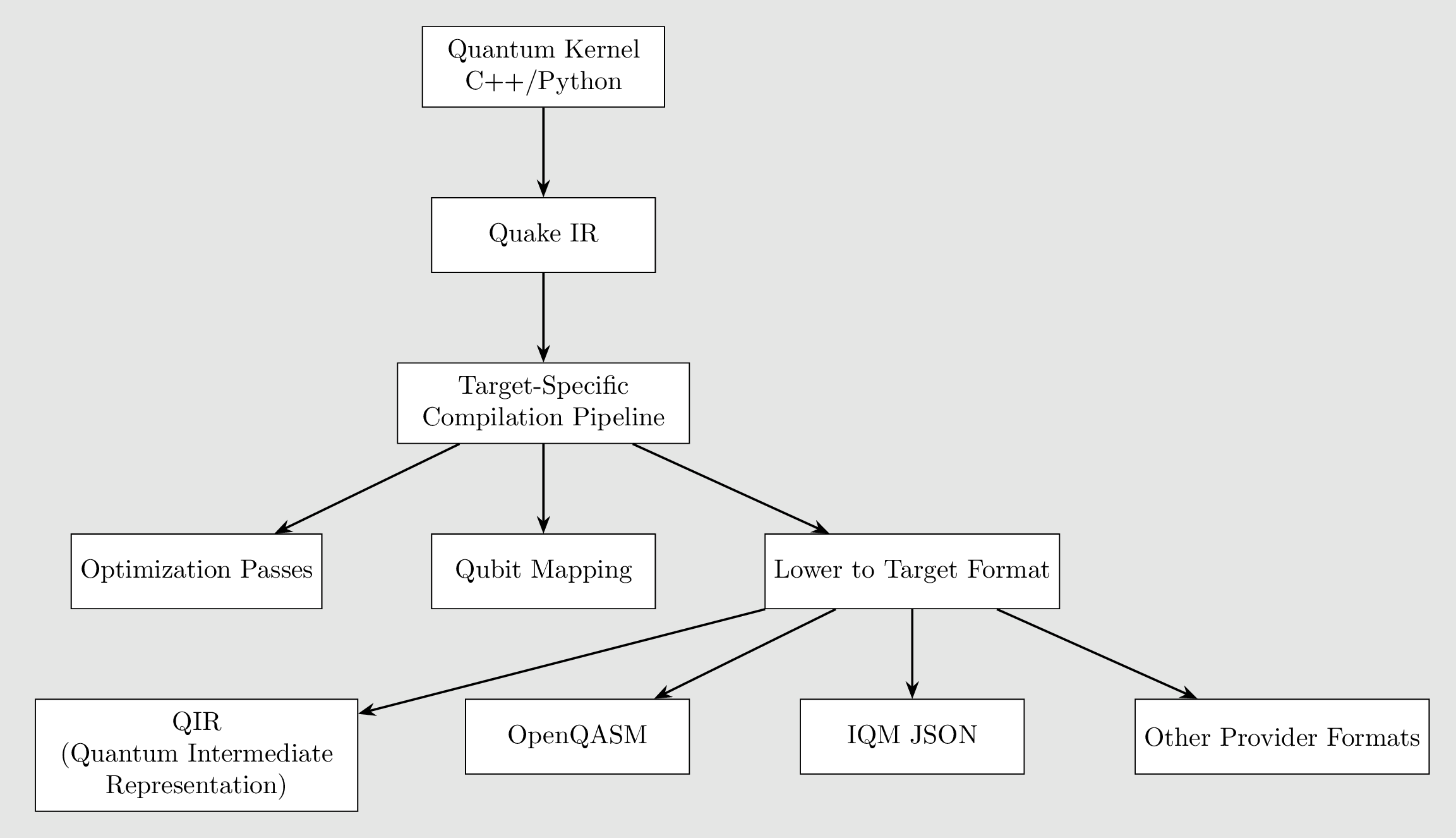
You write code using CUDA-Q's syntax:
To target MQSS via MQP (REST API)
To target MQSS via HPC (coming soon, not supported yet by the MQSS v1)
Once the binary of your application was successfully generated. You can execute your application to submit quantum circuits to the MQSS, as follows:
The environment variable MQSS_MQP_TOKEN is used to specify the path of a text file containing a token to access to the MQP. To generate a valid token please go to the Munich Quantum Portal (MQP).
A configuration file is a requirement to send additional information to be used at runtime by the MQSS.
The environment variable CUDAQ_MQSS_CONFIGURATION has to be defined in order to include the configuration file during runtime.
The configuration file might contain the following information:
n_shots is the number of shots required to execute the quantum task. This is annotated by MQSS CUDA-Q Adapter and it is not required to be defined in the configuration file.transpiler_flag is a flag indicating if the MQSS has to perform transpilation. true indicates the flag is active, false otherwise.submit_time is the submission time of the task. This is annotated by MQSS CUDA-Q Adapter on each submitted task and it is not required to be defined in the configuration file.circuit_file_type is the circuit type submitted to the MQSS. The supported file types at the moment are: QASMi, Quake, and QIR.preferred_qpu specifies the selected preferred QPU where the submitted jobs will be executed.restricted_resource_names specifies the restricted QPUs when submitting a job the MQSS.priority integer value that specified the priority level of the submitted.user_identity specifies the identity of the user.optimisation_level specifies the optimization level. Supported levels: 0, 1, 2, and 3.via_hpc is a flag specifying if the job is submitted via HPC or MQP. true indicates the job is submitted via HPC, false via MQP. This is annotated by MQSS CUDA-Q Adapter on each submitted task and it is not required to be defined in the configuration file.In the following an example of a configuration file: